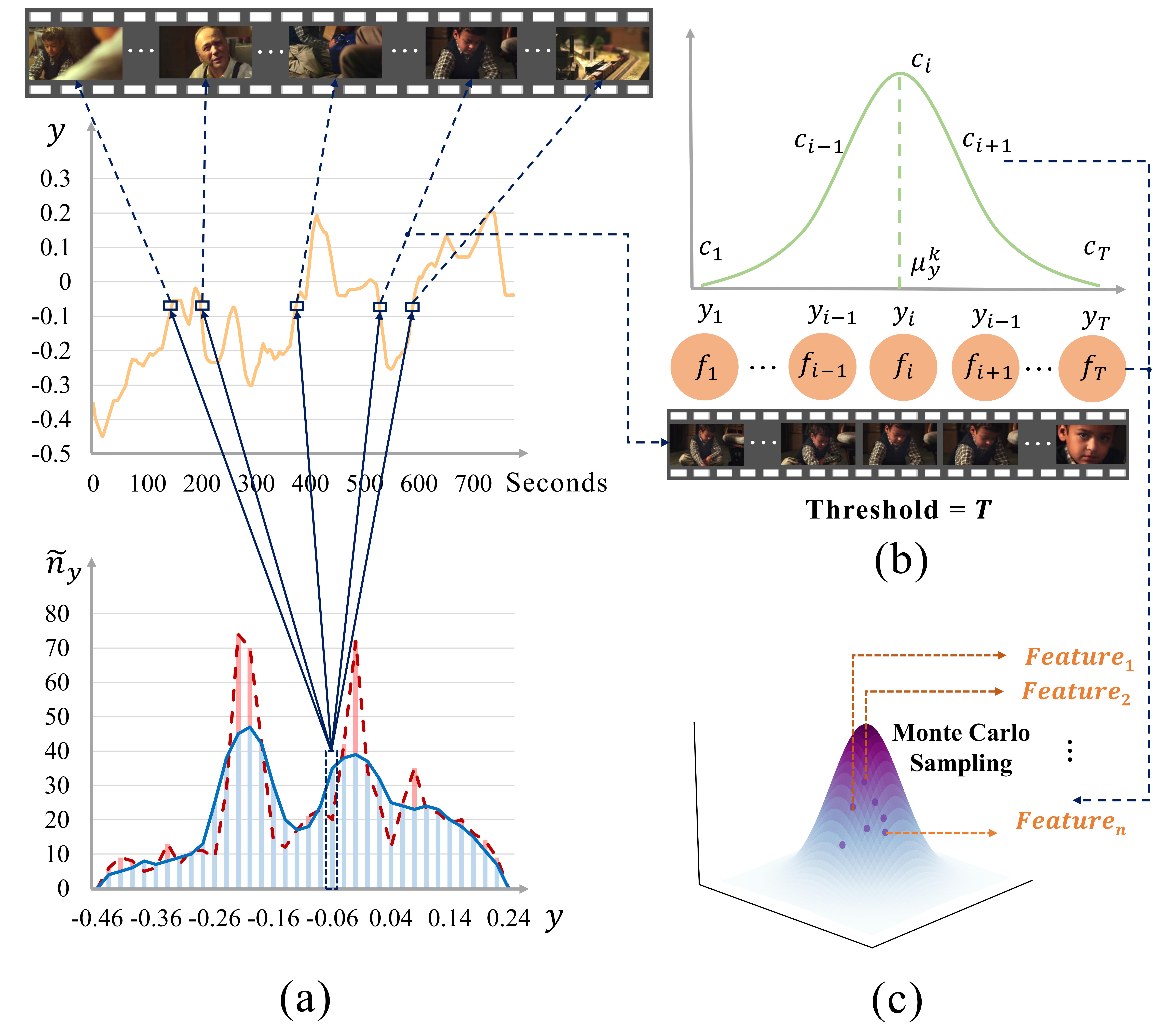
Learning subjective time-series data via Utopia Label Distribution Approximation
Pattern Recognition, 2025
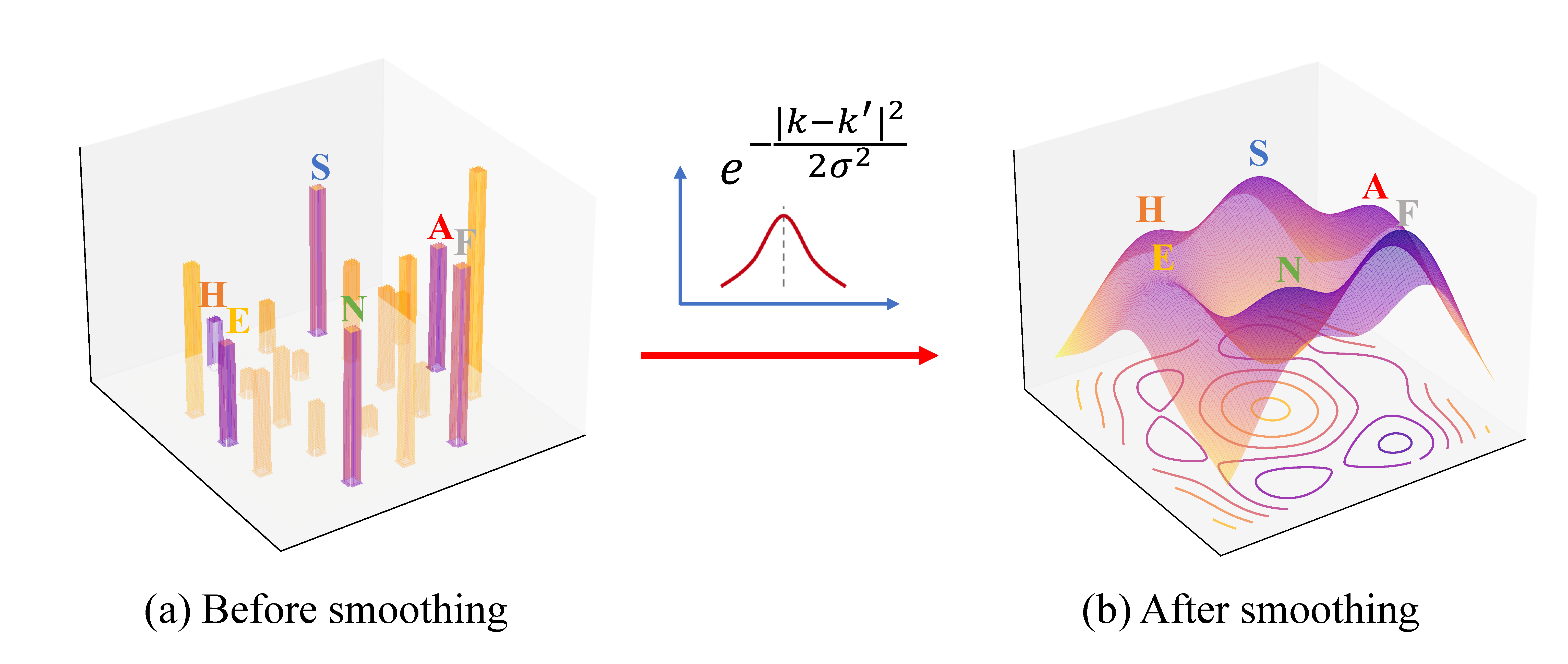
Subjective time-series regression (STR) tasks have gained increasing attention recently. However, most existing methods overlook the label distribution bias in STR data, which results in biased models. Emerging studies on imbalanced regression tasks, such as age and depth estimations, hypothesize the label distribution is uniform and known. But in reality, the label distribution of test set in STR tasks is usually non-uniform and unknown. Moreover, the time-series data exhibits continuity in both temporal context and label spaces, which has not been addressed by existing methods. To tackle these issues, we propose a Utopia Label Distribution Approximation (ULDA) method, which approximates the training label distribution to the real-world but unknown (utopia) label distribution for calibrating the training and test sets. The utopia label distribution is generated by convolving the original one using a Gaussian kernel. ULDA also has two new devised modules (Time-slice Normal Sampling (TNS) generating required new samples and Convolution Weighted Loss (CWL) lowering learning weights for redundant samples), which not only assist the model training, but also maintain the sample continuity in temporal context space. Extensive experiments demonstrate that ULDA lifts the state-of-the-art performance on STR tasks and shows a considerable generalization ability to other time-series tasks.